
Flume collects and aggregates data from almost any source into a persistent store such as HDFS.
Flume Configuration
Install Flume
Cloudera Manager distributes Flume in CDH and offers the following services:
- Flume Agent – Flume is used to retrieve data. You do not need many flume agents, and they can share a host with Hdfs DataNodes, Mapredue TaskTrackers and and HBase RegionServers. However, we should keep Flume on its own server, sharing a network with the many other Flume servers in their own cluster (network access from the Flume service is only needed to Cloudera Manager, ZooKeeper, HBase, and HDFS to write out to storage). Make sure there is an HBase Gateway on the Flume node to keep the HBase configurations up-to-date. Flume is dependent on the Zookeeper service.
Configure Flume
Data Flow Model
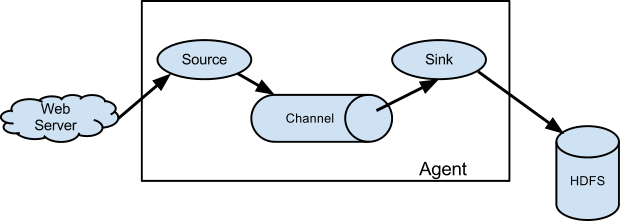
A Flume source consumes events delivered to it by an external source like a web server. When a Flume source receives an event, it stores it into one or more channels. The channel is a passive store that keeps the event until it’s consumed by a Flume sink. The sink removes the event from the channel and puts it into an external repository like HDFS (via Flume HDFS sink) or forwards it to the Flume source of the next Flume agent (next hop) in the flow. The source and sink within the given agent run asynchronously with the events staged in the channel.
When To Use Flume
If you need to ingest textual log data into Hadoop/HDFS then Flume is the right fit for your problem, full stop. For other use cases, here are some guidelines:
Flume is designed to transport and ingest regularly-generated event data over relatively stable, potentially complex topologies. The notion of “event data” is very broadly defined. To Flume, an event is just a generic blob of bytes. There are some limitations on how large an event can be – for instance, it cannot be larger than what you can store in memory or on disk on a single machine – but in practice, flume events can be everything from textual log entries to image files. The key property of an event is that they are generated in a continuous, streaming fashion. If your data is not regularly generated (i.e. you are trying to do a single bulk load of data into a Hadoop cluster) then Flume will still work, but it is probably overkill for your situation. Flume likes relatively stable topologies. Your topologies do not need to be immutable, because Flume can deal with changes in topology without losing data and can also tolerate periodic reconfiguration due to fail-over or provisioning. It probably won’t work well if you plant to change topologies every day, because reconfiguration takes some thought and overhead.